HTMLParser源码解析
最近有解析HTML的需求,在Java中,好用的HTML解析框架也比较多,如
JSoup,HTMLParser,JTidy等等。在对比几款框架之后,最终选取了HTMLParser做为第一版实现的框架。所以对HTMLParser的源码进行了一次整理。由于这种解析类的框架内部细节特别多,所以这里并不会特别的关注所有细节,而是侧重梳理HTMLParser整个解析的流程。
类图
对我而言,画类图是学习一个框架源码比较直接的方式,一是有利于自己梳理逻辑,二是以后自己看类图还是会很容易联想起其中的一些细节。所以,这里放出类图,下面会对主要的类源码进行分析。
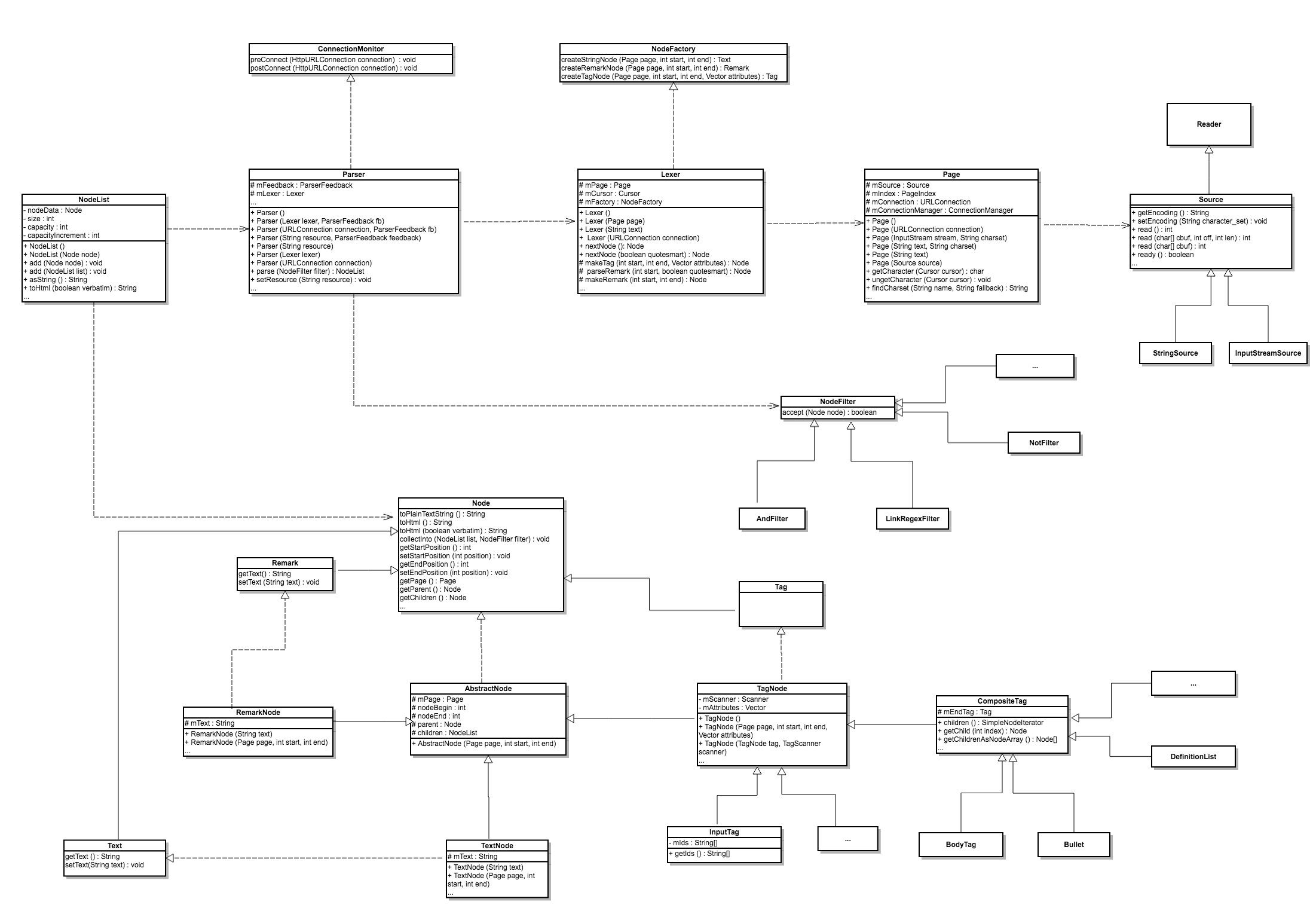
整体介绍
HTMLParser主要靠Node来表示一个节点,细分为Text、Remark和Tag,通过以上三种形式的组合来表示Html,其中Text接口表示纯文本,Remark表示注释,Tag表示标签。
Parser是直接对外提供服务的类,其parse方法可以返回整个HTML文档被转换后的NodeList。
Lexer直译过来为词法分析程序,它主要负责将Html转换为Node节点的,其nextNode方法使我们后文分析的重点。Lexer与Parser的关系就像老板与员工,Parser是对外谈生意的,Lexer才是实打实干活的伙计。
Page表示整个HTML文档,但它里面的主要逻辑都交由Source负责,Source是对HTML源的一个抽象,HTMLParser中有InputStreamSource与StringSource两种实现,前一种可以处理网络或者文件类的流信息,后者可以处理纯文本的HTML。
解析流程
HTMLParser的使用非常简单,如下就是最基本的形式:
Parser parser = new Parser(TEXT);
NodeList list = parser.parse(null);
其中的TEXT可以使纯文本HTML,也可以是一个url,HTMLParser内部会自动判断,但是其判断的逻辑非常简单:
length = resource.length ();
html = false;
for (int i = 0; i < length; i++)
{
ch = resource.charAt (i);
if (!Character.isWhitespace (ch))
{
if ('<' == ch)
html = true;
break;
}
}
只是判断了首个不为空白的字符是否为<。
接下来我们主要看Parser的parse方法:
public NodeList parse (NodeFilter filter) throws ParserException
{
NodeIterator e;
Node node;
NodeList ret;
ret = new NodeList ();
for (e = elements (); e.hasMoreNodes (); )
{
node = e.nextNode ();
if (null != filter)
node.collectInto (ret, filter);
else
ret.add (node);
}
return (ret);
}
整体来看,这个函数并没有做什么东西,唯一可能复杂的就是在变量e(NodeIterator)的获取上,我们追进elements方法:
public NodeIterator elements () throws ParserException
{
return (new IteratorImpl (getLexer (), getFeedback ()));
}
这个方法最终返回了IteratorImpl实例,getLexer方法获取了前面说过负责将Html转换为Node节点的Lexer,Lexer的实例是在Parser的构造函数中创建的,getFeedback方法返回的是ParserFeedback的一个实例,它的主要作用就是输出一些信息。所以,我们主要来看下IteratorImpl的构造函数的实现:
public IteratorImpl (Lexer lexer, ParserFeedback fb)
{
mLexer = lexer;
mFeedback = fb;
mCursor = new Cursor (mLexer.getPage (), 0);
}
首先,缓存变量lexer与fb,紧接着,生成Cursor变量,这个Cursor用来表示当前处理的位置信息。
紧接着,我们来看IteratorImpl的hasMoreNodes方法:
public boolean hasMoreNodes() throws ParserException
{
boolean ret;
mCursor.setPosition (mLexer.getPosition ());
ret = Page.EOF != mLexer.getPage ().getCharacter (mCursor); // more characters?
return (ret);
}
这里需要明确的是,mLexer是用来处理HTML的,所以它知道当前处理的位置,而这个位置,就用cursor表示。Page表示整个HTML文档,所以,它可以根据cursor的信息来查询当前cursor所对应的字符。因此,上述函数翻译过来就是查看当前处理的节点是否为结束符,如果是,则表示没有更多节点了,返回false。
接下来,来看nextNode函数,这里省略一些异常处理:
ret = mLexer.nextNode ();
if (null != ret)
{
// kick off recursion for the top level node
if (ret instanceof Tag)
{
tag = (Tag)ret;
if (!tag.isEndTag ())
{
// now recurse if there is a scanner for this type of tag
scanner = tag.getThisScanner ();
if (null != scanner)
{
stack = new NodeList ();
ret = scanner.scan (tag, mLexer, stack);
}
}
}
}
return ret;
首先,这个函数的前面逻辑交由了lexer的nextNode函数,所以,lexer的nextNode函数我们肯定要跟进,但这里我们先存个档,记为A,因为一会会回到这里。我们追进nextNode,
public Node nextNode (boolean quotesmart)
throws
ParserException
{
int start;
char ch;
Node ret;
// debugging suppport
if (-1 != mDebugLineTrigger)
{
Page page = getPage ();
int lineno = page.row (mCursor);
if (mDebugLineTrigger < lineno)
mDebugLineTrigger = lineno + 1; // trigger on next line too
}
start = mCursor.getPosition ();
ch = mPage.getCharacter (mCursor);
switch (ch)
{
case Page.EOF:
ret = null;
break;
case '<':
ch = mPage.getCharacter (mCursor);
if (Page.EOF == ch)
ret = makeString (start, mCursor.getPosition ());
else if ('%' == ch)
{
mPage.ungetCharacter (mCursor);
ret = parseJsp (start);
}
else if ('?' == ch)
{
mPage.ungetCharacter (mCursor);
ret = parsePI (start);
}
else if ('/' == ch || '%' == ch || Character.isLetter (ch))
{
mPage.ungetCharacter (mCursor);
ret = parseTag (start);
}
else if ('!' == ch)
{
...
}
else
{
mPage.ungetCharacter (mCursor); // see bug #1547354 <<tag> parsed as text
ret = parseString (start, quotesmart);
}
break;
default:
mPage.ungetCharacter (mCursor); // string needs to see leading foreslash
ret = parseString (start, quotesmart);
break;
}
return (ret);
}
首先,说明一点,对于mPage.getCharacter (mCursor)这段代码而言,首先会返回当前cursor对应的字符,紧接着getCharacter函数内部还会对cursor的位置只能的进行加一,所以这就是整个nextNode函数内部都没有看到对cursor位置移动相关的代码的原因。
对于正常的HTML文件而言,头一个字符都会是<,所以都会进入case '<'这个分支,接下来,会匹配else if ('/' == ch || '%' == ch || Character.isLetter (ch))分支,所以会执行
mPage.ungetCharacter (mCursor);
ret = parseTag (start);
ungetCharacter会智能的回退cursor的字符,执行过后,cursor会回到上一步getCharacter之前的状态。按理说我们此时需要追入parseTag方法, 但这个方法非常长,并且逻辑就比较恶心了,可能会引起您的不适,所以这里就不贴parseTag的代码了,它所做的主要功能是提取出一个标签的名称和标签内的属性。但它并没有彻底解析整个标签。还记得刚刚存档A吗?解析整个标签的逻辑在A那里:
if (ret instanceof Tag)
{
tag = (Tag)ret;
if (!tag.isEndTag ())
{
// now recurse if there is a scanner for this type of tag
scanner = tag.getThisScanner ();
if (null != scanner)
{
stack = new NodeList ();
ret = scanner.scan (tag, mLexer, stack);
}
}
}
可以看到,如果nextNode返回的ret为Tag且部位endTag的话,会执行一个scanner的scan方法,那这个scanner是什么鬼呢?它就是负责解析整个tag标签的神奇boss。它的实现比较多,一般而言,我们更长接触的是CompositeTagScanner,所以我们来看一下CompositeTagScanner的scan方法,这个方法也非常的长,这里我省略了非常多:
do
{
node = lexer.nextNode (false);
if (null != node)
{
if (node instanceof Tag)
{
next = (Tag)node;
name = next.getTagName ();
// check for normal end tag
if (next.isEndTag () && name.equals (ret.getTagName ()))
{
ret.setEndTag (next);
node = null;
}
else if (!next.isEndTag ())
{
// now recurse if there is a scanner for this type of tag
scanner = next.getThisScanner ();
if (null != scanner)
{
node = scanner.scan (next, lexer, stack);
addChild (ret, node);
}
else
addChild (ret, next);
}
}
}
while (null != node);
首先,lexer会迭代出下一个node,如果这个node为Tag,首先会判断是否为当前node的endTag,如果是则表示可以结束当前node的scan。将node制空,结束当前循环。否则的话,会走到else if (!next.isEndTag ())的分支,当心迭代的node可以被scan的话,会执行到node = scanner.scan (next, lexer, stack);这句,相当于递归的进行节点的扫描。知道找到最终节点的endTag,结束当前循环。表示遍历完一个Node。
当然,上面的scan函数做了非常多的精简,真实的scan函数,因为细节点很多,所以实现远比这复杂的多。
综上,通过对Lexer的nextNode函数与Scan的scan函数之间的不断配合,HTMLParser就完成了整个解析。我们也可以得到一个非常重要的结论: HTMLParser的遍历是深度优先的!
参考
http://htmlparser.sourceforge.net/
on