细说编码
基本概念
位
位(bit)是指计算机里存放的二进制值(0/1)
字节
8个位组合成的“位串”称为一个字节
字符集(Charset)
是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码
是指定义一套规则,将真实世界里的字母/字符与计算机的二进制序列进行相互转化。
如果将上面的三个概念整理出来就是:字符编码是由位(0,1)构成的不同字节序列来表示不同的文字。说白了,字符编码是一套规则。每种字符编码对应着自己的字符集,儿规则定义了哪些字节序列表示字符集里面的哪些文字。
常用编码
ASCII字符集&编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它是比较早的字符编码,主要用于显示现代英语,
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符.
EASCII
很明显,ASCII编码所表示字符太少(只用了7位表示一个字符),局限太大。我们想到最简单的办法就是将没有用到的第8位也用上,这样能表达的字符个数就达到了2^8 =256个,相比较原来,增长了一倍, 这个编码规就被称为EASCII。EASCII基本解决了整个西欧的字符编码问题。
ISO 8859
后来人们发现258个字符也不够用了,于是推出了ISO 8859,采取的不再是单个独立的编码规则,而是由一系列的字符集(共15个)所组成,分别称为ISO 8859-n(n=1,2,3…11,13…16,没有12)。其每个字符集对应不同的语言,如ISO 8859-1对应西欧语言,ISO 8859-2对应中欧语言等。其中大家所熟悉的Latin-1(用过mysql的应该很了解)就是ISO 8859-1的别名,它表示整个西欧的字符集范围。 需要注意的一点的是,ISO 8859-n与ASCII是兼容的,即其0000000(0x00)-01111111(0x7f)范围段与ASCII保持一致,而10000000(0x80)-11111111(0xFF)范围段被扩展用到不同的字符集。
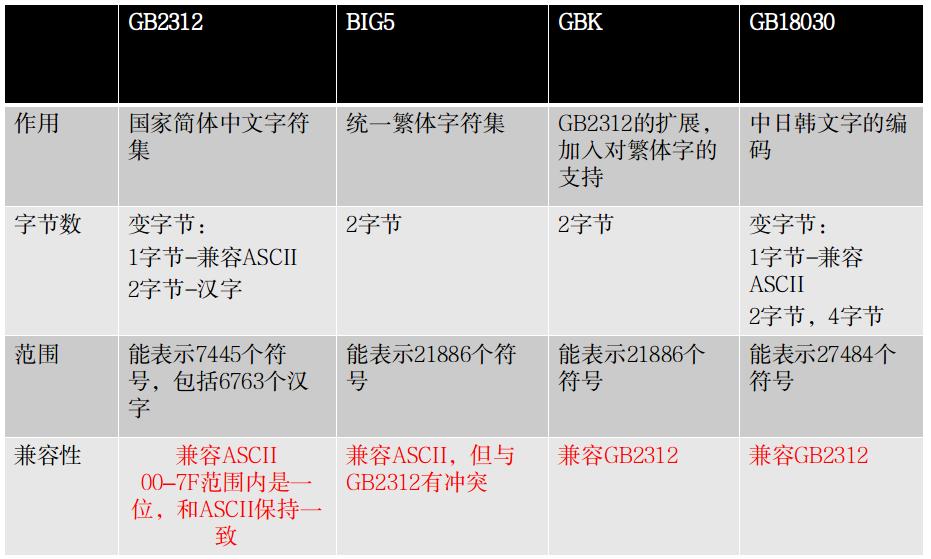
GB2312字符集&编码
互联网时代的闭关锁国也阻止不了我国的发展,天朝有了网络后,发现之前的字符编码都不能显示中文,所以,必须设计一套编码规则用于将汉字转换为计算机可以接受的系统数字。于是就有了GB2312,全称位全称《信息交换用汉字编码字符集·基本集》.GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
GBK编码
GBK编码是对GB2312的扩展,主要增加了对繁体字的支持,它是兼容 GB2312的,只不过GB2312是国家认证的编码,血统比较纯正,而GBK属于野路子,不过如果不考虑国际化,GBK对于中文的项目足够了。GB2312和GBK都属于中文编码,当然还有一些其它的中文编码,下面有一张图可以很清晰的描述这些编码的关系:
Unicode
以上可以看到,针对不同的语言采用不同的编码,有可能导致冲突与不兼容性,如果我们打开一份字节序文件,如果不知道其编码规则,就无法正确解析其语义,这也是产生乱码的根本原因。有没有一种规则是全世界字符统一的呢?当然有,Unicode就是一种。为了能独立表示世界上所有的字符,Unicode采用4个字节表示一个字符,这样理论上Unicode能表示的字符数就达到了231 = 2147483648 = 21 亿左右个字符,完全可以涵盖世界上一切语言所用的符号
UTF-*
常用的UTF-*系列编码为UTF-32、UTF-16、UTF-8三位仁兄.32、16、8的意思是用来编码的位数,如UTF-32用32位即4字节表示一个编码,这样表示的字符很多,但也浪费严重,于是有了用16位表示一个字符的UTF-16。但人们觉得这还不够,于是就有了UTF-8,注意,这里的8不是简单的表示UTF-8用8个位表示一个字符,实际上,UTF-8是一种针对Unicode的可变长度字符编码(这里变长字符编码可以借助哈夫曼编码来理解,即常用的字符所用的位数小,不常用的字符所占位数多。),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
总结
-
ASCII属于祖宗级别的人物,EASCII和ISO 8859属于它的儿子辈,都是对它进行了扩展并保持了兼容。
-
GB2312和GBK属于对中文进行的编码,GB2312属于爸爸,GBK属于儿子,他继承了父亲的血统并进行了扩展,也都对ASCII保持了兼容。所以GB2312和GBK都属于ASCII的晚辈。
-
Unicode迎来了编码大一统的时代,UTF-*是Unicode的几种变体,最常用的是UTF-8.其实UTF-8也是ASCII的一个晚辈,也就是说一个纯ASCII字符串也是一个合法的UTF-8字符串。
参考资料:
http://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81
http://sharecore.net/blog/2014/08/10/zi-fu-bian-ma-chang-shi-ji-wen-ti-jie-xi/
http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
on